知识点
zip伪加密
原理
一个 zip 文件由三部分组成:压缩源文件数据区 + 压缩源文件目录区 + 压缩源文件目录结束标志。
1、压缩源文件数据区:
在这个数据区中每一个压缩的源文件/目录都是一条记录,记录的格式如下:
文件头 + 文件数据 + 数据描述符
- 文件头结构
| 组成 | 长度 |
|---|---|
| 文件头标记 | 4 bytes (0x04034b50) |
| 解压文件所需 pkware 版本 | 2 bytes |
| 全局方式位标记 | 2 bytes |
| 压缩方式 | 2 bytes |
| 最后修改文件时间 | 2 bytes |
| 最后修改文件日期 | 2 bytes |
| CRC-32 校验 | 4 bytes |
| 压缩后尺寸 | 4 bytes |
| 未压缩尺寸 | 4 bytes |
| 文件名长度 | 2 bytes |
| 扩展记录长度 | 2 bytes |
| 文件名 | 不定长度 |
| 扩展字段 | 不定长度 |
-
文件数据
-
数据描述符
| 组成 | 长度 |
|---|---|
| CRC-32 校验 | 4 bytes |
| 压缩后尺寸 | 4 bytes |
| 未压缩尺寸 | 4 bytes |
这个数据描述符只在全局方式位标记的第3位设为 1 时才存在,紧接在压缩数据的最后一个字节后。这个数据描述符只用在不能对输出的 zip 文件进行检索时使用。例如:在一个不能检索的驱动器 (如:磁带机上) 上的 zip 文件中。如果是磁盘上的 zip 文件一般没有这个数据描述符。
2、压缩源文件目录区:
在这个数据区中每一条记录对应在压缩源文件数据区中的一条数据。
| 组成 | 长度 |
|---|---|
| 目录中文件文件头标记 | 4 bytes (0x02014b50) |
| 压缩使用的 pkware 版本 | 2 bytes |
| 解压文件所需 pkware 版本 | 2 bytes |
| 全局方式位标记 | 2 bytes |
| 压缩方式 | 2 bytes |
| 最后修改文件时间 | 2 bytes |
| 最后修改文件日期 | 2 bytes |
| CRC-32 校验 | 4 bytes |
| 压缩后尺寸 | 4 bytes |
| 未压缩尺寸 | 4 bytes |
| 文件名长度 | 2 bytes |
| 扩展字段长度 | 2 bytes |
| 文件注释长度 | 2 bytes |
| 磁盘开始号 | 2 bytes |
| 内部文件属性 | 2 bytes |
| 外部文件属性 | 4 bytes |
| 局部头部偏移量 | 4 bytes |
| 文件名 | 不定长度 |
| 扩展字段 | 不定长度 |
| 文件注释 | 不定长度 |
3、压缩源文件目录结束标志:
| 组成 | 长度 |
|---|---|
| 目录结束标记 | 4 bytes (0x02014b50) |
| 当前磁盘编号 | 2 bytes |
| 目录区开始磁盘编号 | 2 bytes |
| 本磁盘上记录总数 | 2 bytes |
| 目录区中记录总数 | 2 bytes |
| 目录区尺寸大小 | 4 bytes |
| 目录区对第一张磁盘的偏移量 | 4 bytes |
| zip 文件注释长度 | 2 bytes |
| zip 文件注释 | 不定长度 |
原文来自 —–> here
实例
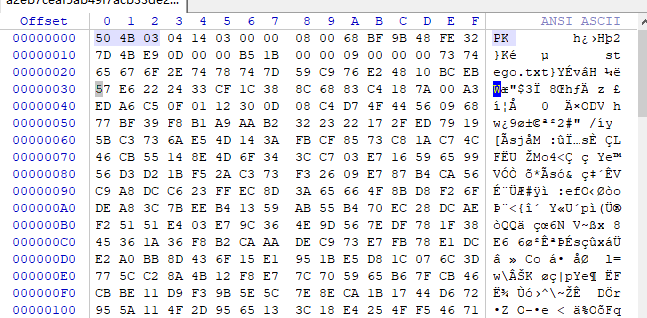
压缩源文件数据区:
50 4B 03 04: 这是头文件标记 (0x04034b50)
14 03: 解压文件所需 pkware 版本
00 00: 全局方式位标记 (有无加密),头文件标记后 2 bytes
08 00: 压缩方式
68 BF: 最后修改文件时间
9B 48: 最后修改文件日期
FE 32 7D 4B: CRC-32校验
E9 0D 00 00: 压缩后尺寸
B5 1B 00 00: 未压缩尺寸
09 00: 文件名长度
00 00: 扩展记录长度
......................
压缩源文件目录区:
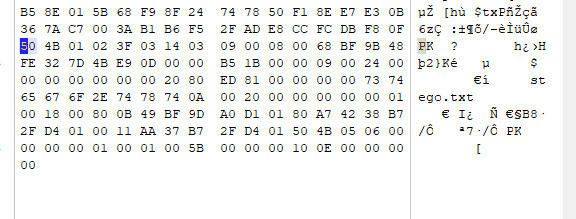
50 4B 01 02: 目录中文件文件头标记 (0x02014b50)
3F 03: 压缩使用的 pkware 版本
14 03: 解压文件所需 pkware 版本
09 00: 全局方式位标记 (有无加密,伪加密的关键) 目录文件标记后 4 bytes
08 00: 压缩方式
68 BF: 最后修改文件时间
9B 48: 最后修改文件日期
FE 32 7D 4B: CRC-32 校验 (4b7d32fe)
E9 0D 00 00: 压缩后尺寸 (237)
B5 1B 00 00: 未压缩尺寸 (208)
09 00: 文件名长度
24 00: 扩展字段长度
00 00: 文件注释长度
00 00: 磁盘开始号
00 00: 内部文件属性
20 80 ED 81: 外部文件属性
00 00 00 00: 局部头部偏移量
..............................
压缩源文件目录结束标志:

50 4B 05 06: 目录结束标记
00 00: 当前磁盘编号
00 00: 目录区开始磁盘编号
01 00: 本磁盘上记录总数
01 00: 目录区中记录总数
5B 00 00 00: 目录区尺寸大小
10 0E 00 00: 目录区对第一张磁盘的偏移量
00 00: zip 文件注释长度
操作
以上详细的介绍了各个部分的含义,修改其压缩源文件目录区的全布局方式标记比特值之后即可对文件加密或解密。
- 压缩源文件数据区:
50 4B 03 04: 这是头文件标记
- 压缩源文件目录区:
50 4B 01 02: 目录中文件文件头标记
3F 03: 压缩使用的 pkware 版本
14 03: 解压文件所需 pkware 版本
09 00: 全局方式位标记 (有无加密,伪加密的关键) 目录文件标记后 4 bytes
# 在全局方式位标记这里来看是否有加密, 09 00 代表有加密, 00 00 代表无加密
可以修改这里来更改伪加密 全局方式位标记的四个数字中只有第二个数字对其有影响,其
它不管为什么,都不会影响它的加密属性 也就是 9 代表加密,0 代表无加密
- 压缩源文件目录结束标志:
50 4B 05 06: 目录结束标记
我们将压缩源文件目录区的全局方式位标记的09 00改为00 00,即可破解伪加密,打开压缩包。
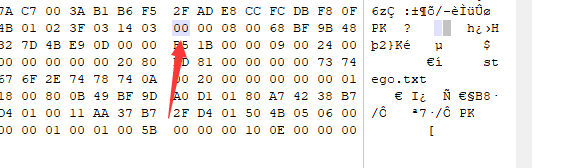
成功!
Base64 隐写
base64 编码原理
base64 是一种基于 64 个可打印字符表示二进制数据的表示方法,其一大特点是能够将不可打印字符编码为可打印字符。
base64 可打印字符及其索引
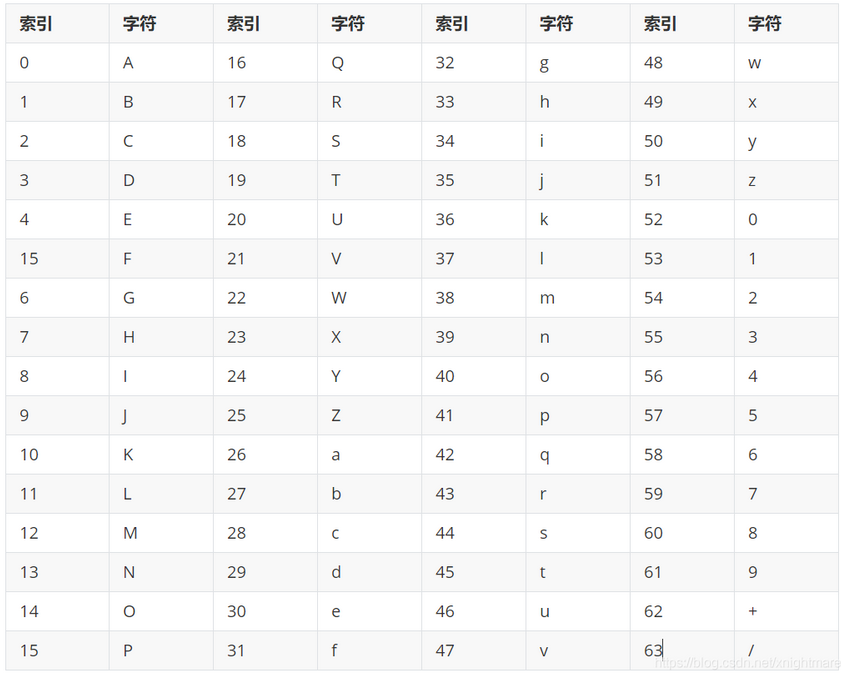
简单来说,就是 A-Z a-z 0-9 + / 这64个可打印字符。
编码时,将要编码的内容转换为二进制数据,每6位作为一组,从表中找到对应的字符。因为ASCII编码8位表示一个字符,3个ASCII刚好可以编码成4个字符 (3 * 8 = 4 * 6),因此一般以3个ASCII字符为一个编码的基本单位:

但需要编码的文本字节数并不总是3的倍数,不可避免会遇到最后只剩下2个或1个字符的情况,需要特殊处理:
%3 = 2 的情况:

%3 = 1 的情况:

base64 隐写的原理
从base64编码的原理我们很自然的推出base64解码的过程:
- 丢掉末尾的所有
=; - 每个字符查表转换为对应的6位索引,得到一串二进制字符串;
- 从头开始,每次取8位转换为对应的ASCII字符,如果不足8位则丢弃。
在解码的第三步中,会有部分数据被丢弃 (即不会影响解码的结果),这些数据正是我们在编码过程中补的0 (上特殊处理图中加粗的部分)。也就是说,如果我们在编码过程中不全用0填充,而是用其他的数据填充,仍然可以正常编码解码,因此这些位置可以用于隐写。
解开隐写的方法就是将这些不影响解码结果的位提取出来组成二进制串,然后转换为ASCII字符串。
脚本如下: (适用于 python2 情况)
其中:
-
注意:Windows下生成的文本文件,换行为\r\n;在Linux下运行脚本,需要先把文本文件换行的\r\n替换为\n,反之亦然。
- zfill():返回指定长度的字符串,原字符串右对齐,前面填充0。
- index():指定字符串中是否含有要查找的子字符串,返回包含子字符串开始处的索引值,否则抛出异常。
def get_base64_diff_value(s1, s2):
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
res = 0
for i in xrange(len(s2)):
if s1[i] != s2[i]:
return abs(base64chars.index(s1[i]) - base64chars.index(s2[i]))
return res
def solve_stego():
with open('D:/stego.txt', 'rb') as f:
file_lines = f.readlines()
bin_str = ''
for line in file_lines:
steg_line = line.replace('\n', '')
norm_line = line.replace('\n', '').decode('base64').encode('base64').replace('\n', '')
diff = get_base64_diff_value(steg_line, norm_line)
pads_num = steg_line.count('=')
if diff:
#print bin(diff)
bin_str += bin(diff)[2:].zfill(pads_num * 2)
else:
bin_str += '0' * pads_num * 2
res_str = ''
for i in xrange(0, len(bin_str), 8):
res_str += chr(int(bin_str[i:i+8], 2))
print res_str
solve_stego()
固件分析(多重文件解析)
binwalk
binwalk 解析一下:
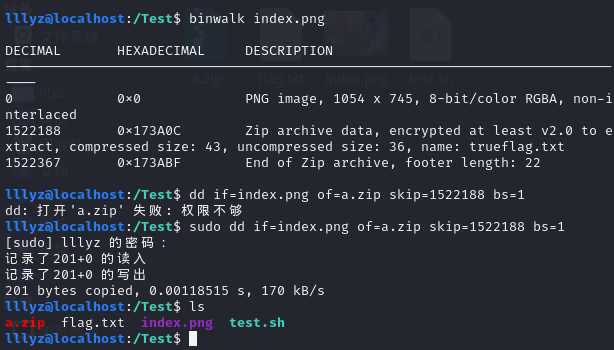
发现其中还有 zip 文件,将其提取出来。解压,用到之前得到的密码,得到 flag。
#binwalk dd 命令分离文件
dd if=index.png of=a.zip skip=1522188 bs=1
if 指定输入文件,of 指定输出文件,skip 指定从文件开头跳过 x 个块后开始复制,
bs 设置每次读写块的大写为 x 字节。
binwalk -e 文件路径 #得到分离后的文件 直接命令不需要像上面一样自己规定文件位置
其他分解方法:
https://www.cnblogs.com/jiaxinguoguo/p/7351202.html
http://www.bugku.com/forum.php?mod=viewthread&tid=115&extra=page%3D1
各类文件的文件头标志 (二进制形式)
- JPEG (jpg),文件头:FFD8FF;文件尾:FFD9。
- PNG (png),文件头:89504E47;
- GIF (gif),文件头:47494638
实例题
base64stego
通过上述方法将压缩文件打开后得到 stego.txt 文件,打开后看起来都是 base64 加密,去网站解密?当然不会这么简单。
在网站解密后得到:
Steganography is the art and science of writing hidden messages in such a way that no one
翻译:隐写术是一门艺术和科学,它以这样一种方式书写隐藏的信息。
提示了 隐写。
直接用上述的脚本运行得到结果:

功夫再高也怕菜刀
刚开始得到一个.pcapng文件,我这里用了 binwalk 分离了文件,得到一个空 flag.txt,然后还有其他文件,其中有一个 zip文件,发现是加密的,里面有flag.txt,所以猜想我们要得到密码。
wireshark查找
在 wireshark 上查找 flag.txt,要设置为 分组字节流:
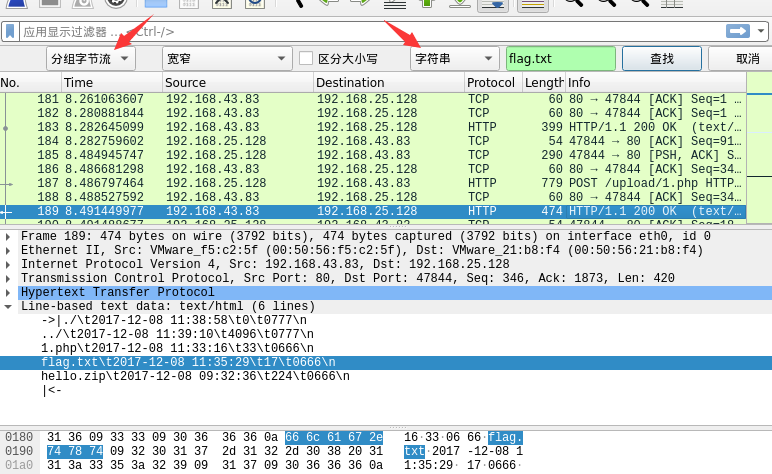
会有很多的匹配,这里我用了 1150 的,右键跟踪TCP流:
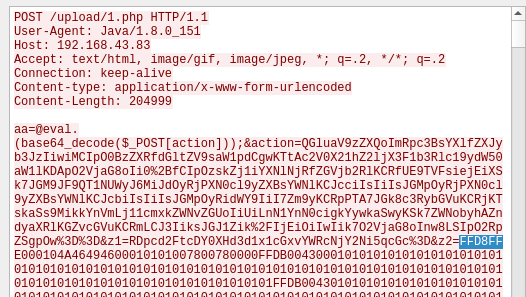
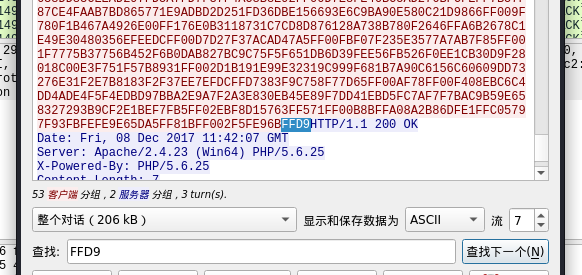
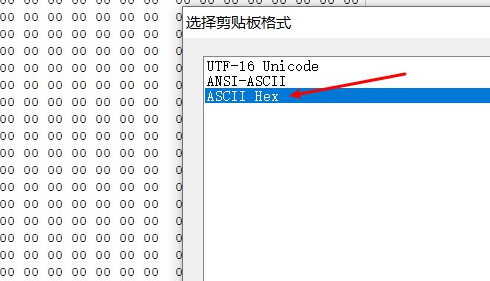
从最开始的 FFD8FF 到最后的 FFD9(FFD8FF是 jpg文件头,FFD9是其文件尾),将其复制到 winhex中。
在 winhex 中新键文件,以 ASCII Hex 的形式复制进去,保存为 jpg 格式:
得到图片,图片上有一段字符串,即为压缩包密码。即可得到flag。